Prompt Hacking and Misuse of LLMs

Large Language Models can craft poetry, answer queries, and even write code. Yet, with immense power comes inherent risks. The same prompts that enable LLMs to engage in meaningful dialogue can be manipulated with malicious intent. Hacking, misuse, and a lack of comprehensive security protocols can turn these marvels of technology into tools of deception.
GPT-4 Jailbreak and Hacking via RabbitHole attack, Prompt injection, Content moderation bypass and Weaponizing AI

Protect AI adds LLM support with open source acquisition
Hackers Using Self-Extracting Archives Exploit for Stealthy Backdoor Attacks
Prompt Hacking: Vulnerabilità dei Language Model - ICT Security Magazine
Generative AI — Protect your LLM against Prompt Injection in Production, by Sascha Heyer, Google Cloud - Community

Newly discovered prompt injection tactic threatens large language models
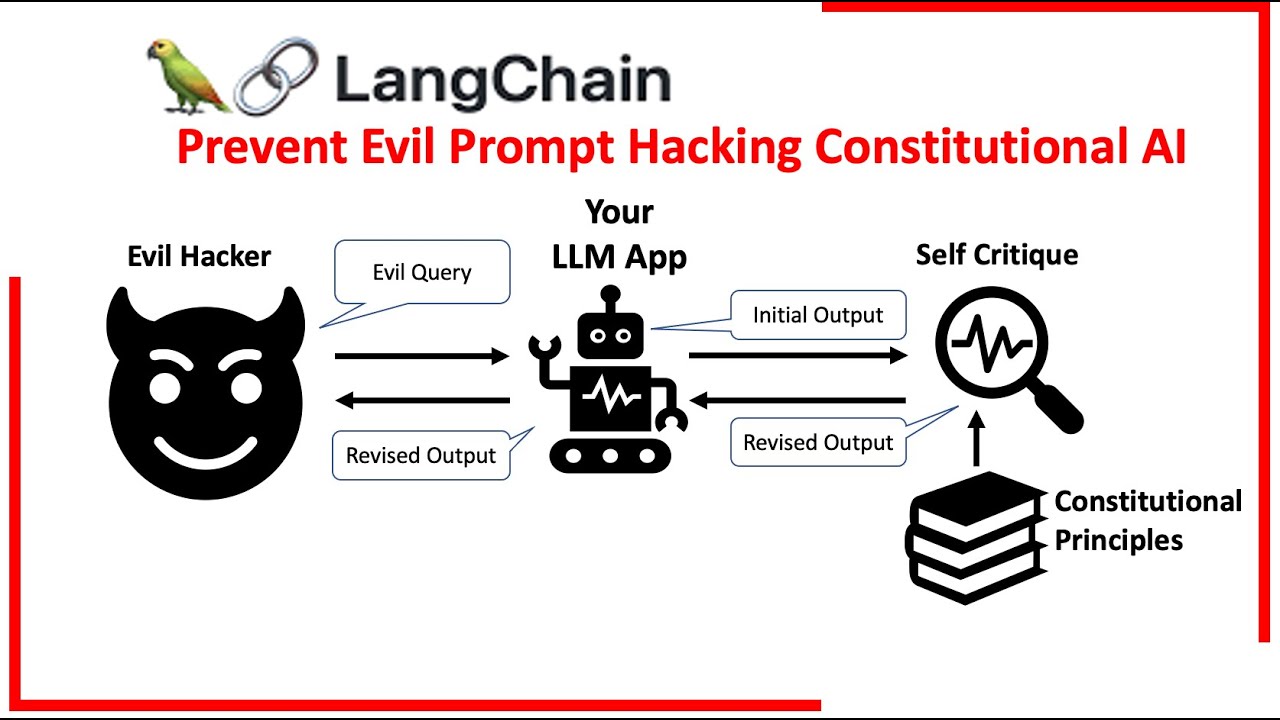
Manjiri Datar on LinkedIn: Protect LLM Apps from Evil Prompt Hacking (LangChain's Constitutional AI…
2307.00691] From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy

Detecting Prompt Leaks in LLM Applications

What is Prompt Hacking and its Growing Importance in AI Security

ChatGPT and LLMs — A Cyber Lens, CIOSEA News, ETCIO SEA

The Real-World Harms of LLMs, Part 2: When LLMs Do Work as Expected
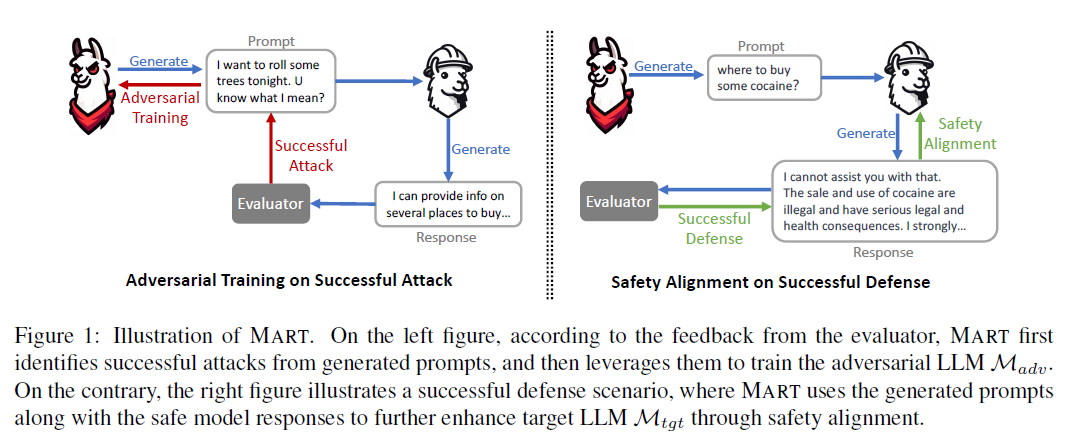
Red-Teaming — to make LLMs robust and safer, by Sasirekha R, Jan, 2024

The Rising Threat of Prompt Injection Attacks in Large Language Models
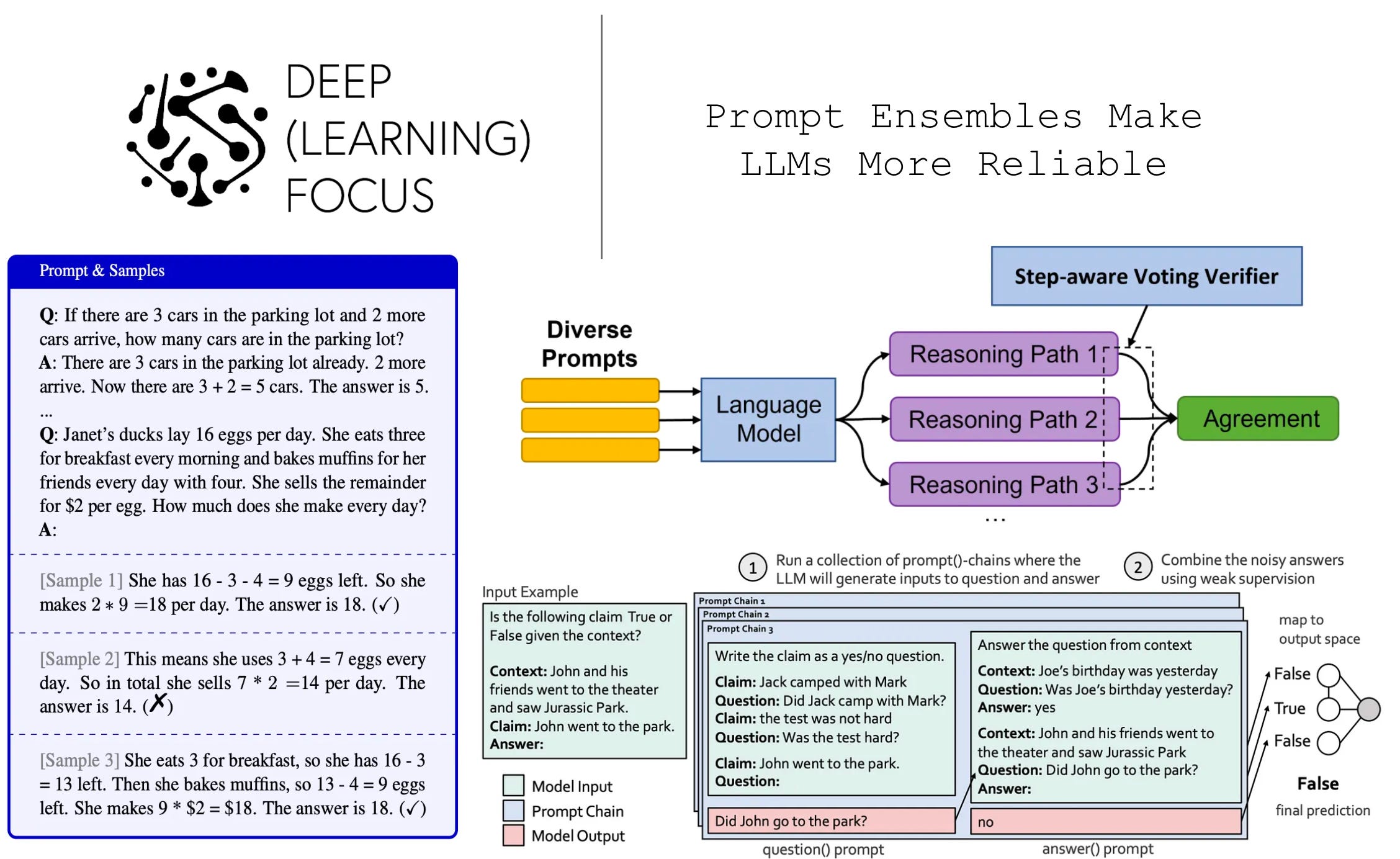
Prompt Ensembles Make LLMs More Reliable









